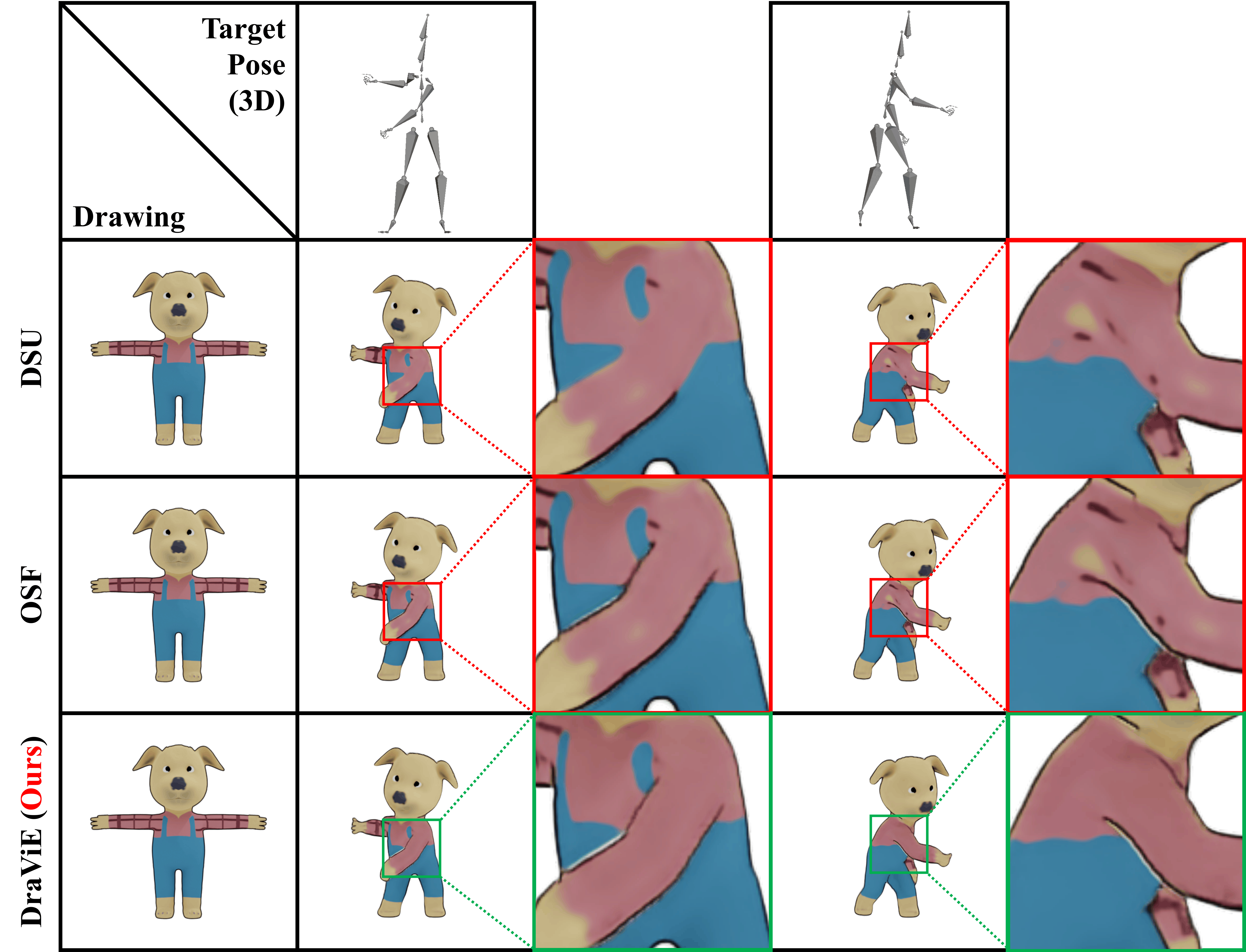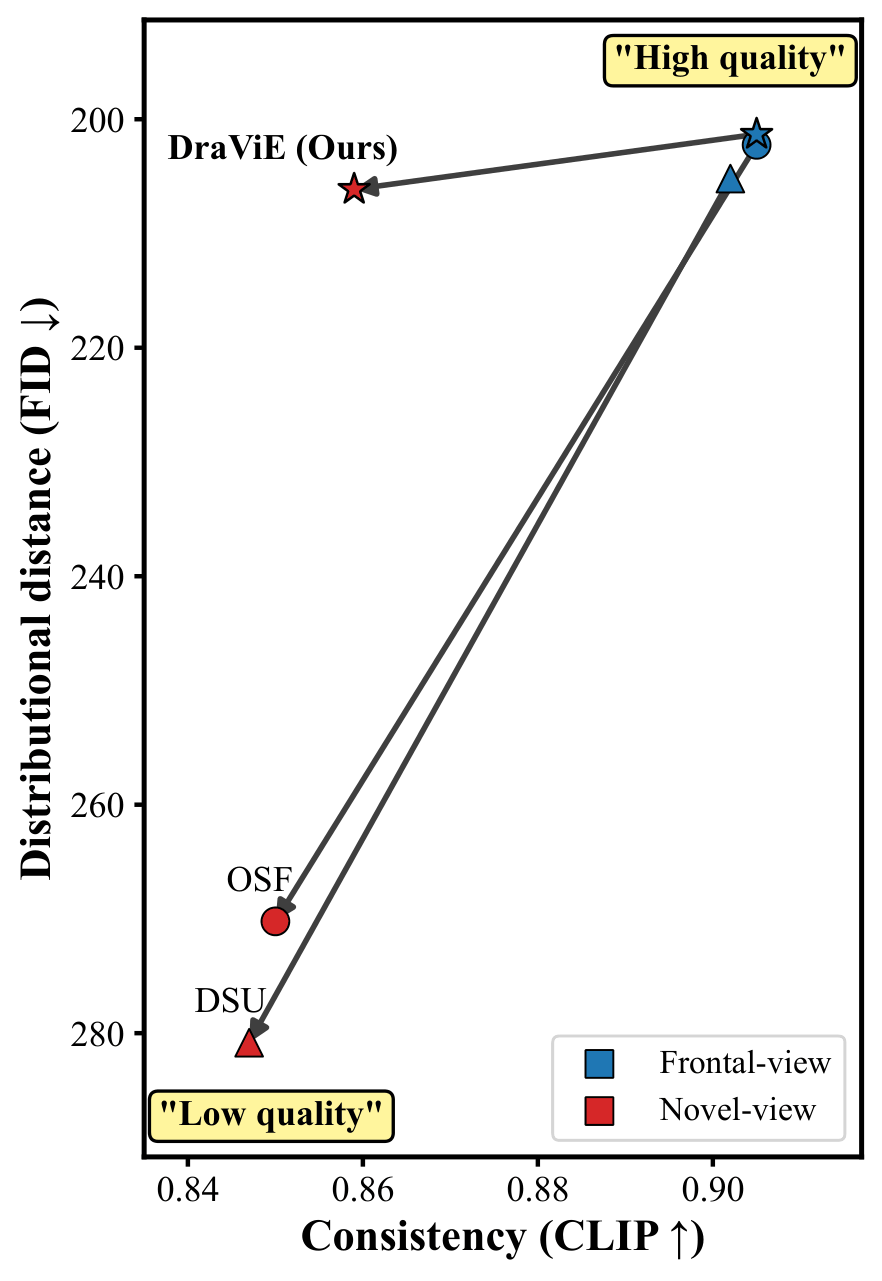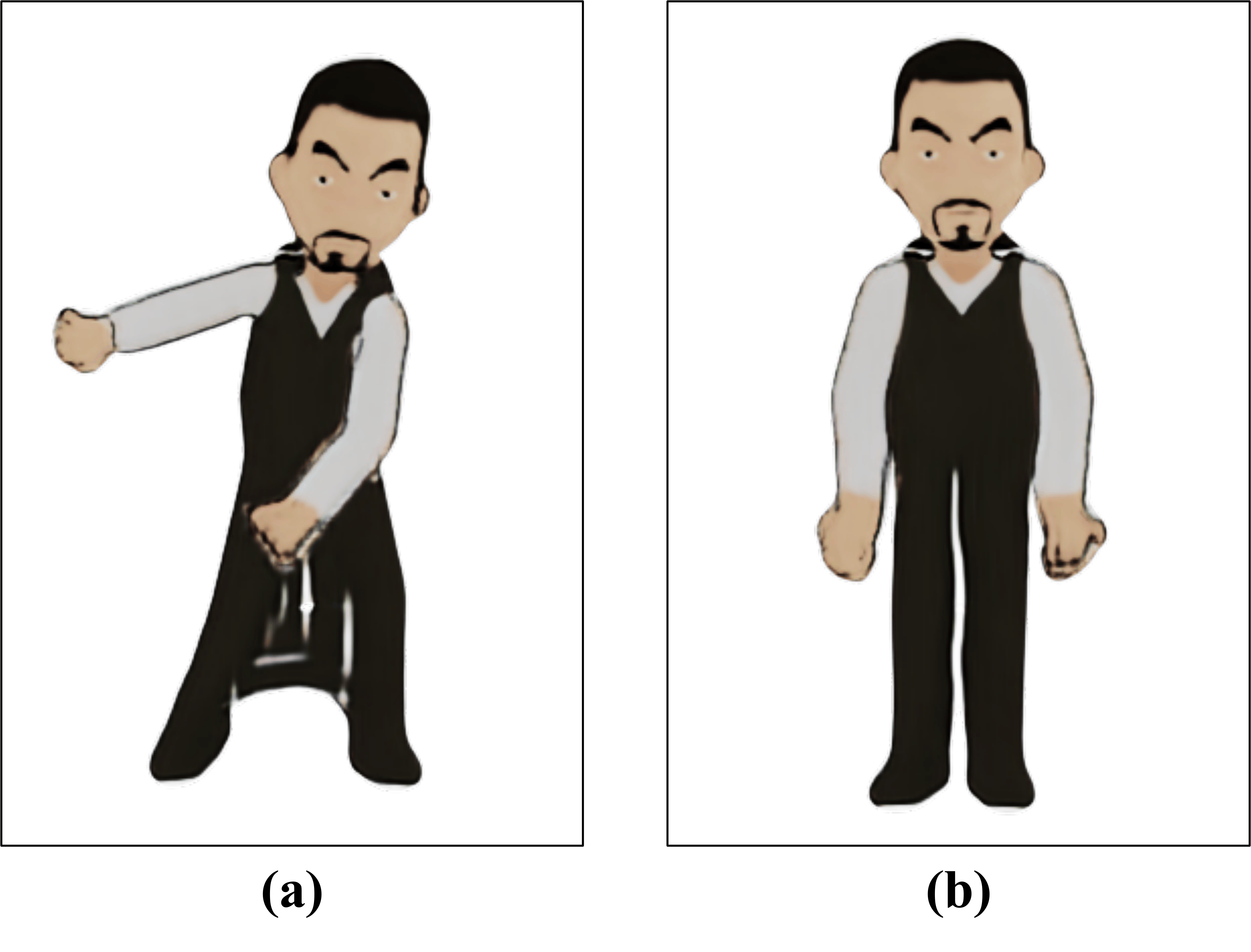
Generating animation from a single 2D drawing is challenging because the output must preserve character appearance while remaining plausible and temporally coherent under motion. Existing drawing-based 3D animation pipelines often use sample-wise 2D refinement to align animated renderings with the input image, but such optimization tends to overfit to the observed view and fails to correct projection-induced artifacts in novel views. To address this limitation, we introduce SPECSIA-15K, a paired stylization dataset for novel-view enhancement in drawing-based 3D animation, constructed from multi-view renderings of 3DBiCar with 10 views per object and 14,980 artifact-corrupted projection/refinement-target pairs. We further present Drawing-based View Enhancement (DraViE), a lightweight plug-and-play refinement module trained with data-level priors to remove novel-view artifacts while preserving drawing style and motion plausibility. Experiments show consistent gains in novel-view fidelity and temporal coherence with lower per-character adaptation cost than sample-wise fine-tuning.